As complexity intensifies within sophisticated computing, so does the demand for more computing power. On top of that, the need to mine data from the burgeoning mountain of Internet search data has led to huge data centers that must be located close to water to feed their massive equipment cooling systems.
Weather modeling, for instance, continues to drill down into smaller geographical elements to fine-tune accuracy. And longer and more sophisticated encryption keys require greater compute power to crack them.
New tasks are also emerging in fields ranging from advertising to gene sequencing. Companies in the bio-sciences area gain competitive advantage based on the speed they’re able to sequence the genes held in DNA samples. Drug companies rely heavily on computer modeling to identify suitable candidate chemical formulas that may be useful in combating diseases.
In security, the focus has turned to deep packet inspection and application-aware monitoring. Companies now routinely deploy firewalls that are able to break into individual communication streams and identify traffic specific to, say, social networking sites, which can be used to help stop malicious attacks on corporate assets.
The Server Farm Approach
Traditionally, increases in processing requirements are handled with a brute force approach: Develop server farms that simply throw more microprocessor units at a problem. The heightened clamor for these server farms creates new problems, though, such as how to bring enough power to a server room and how to remove the generated heat. Space requirements are another problem, as is the complex management of the server farm to ensure factors like optimal load balancing, in terms of guaranteeing return on investment.
At some point, the rationale for these local server farms runs out as the physical and heat problems become too large. Enter the great savior to these problems, otherwise known as “The Cloud.” In this model, big companies will hire out operating time on huge computing clusters.
In a stroke, companies can make physical problems disappear by offloading this IT requirement onto specialised companies. However, it’s not without problems:
-
Depending on the data, there may be a requirement for high-bandwidth communications to and from the data centre.
-
A third party is added into the value chain, and it will try to make money out of the service based on used computing time.
-
Rather than solving the power problem, it’s simply been moved—exactly the same amount of computing needs to be undertaken, just in a different place.
This final issue, which raises fundamental problems that can’t be solved with traditional processor systems, splits into two parts:
-
Software: Despite advances in software programming tools, optimization of algorithms for execution on multiple processors is still far away. It’s often easy to break down a problem into a number of parallel computations. However, it’s much harder for the software programmer to handle the concept of pipelining, where the output of one stage of operation is automatically passed to the next stage and acted upon. Instead, processors perform the same operation on a large array of data, pass it to memory, and then call it back from memory to perform the next operation. This creates a huge overhead on power consumption and execution time.
-
Hardware: Processor systems are designed to be general. A processor’s data path is typically 32 or 64 bits. The data often requires much smaller resolution, leading to large inefficiencies as gates are clocked unnecessarily. Frequently, it becomes possible to pack data to fill more of the available data width, although this is rarely optimal and adds its own overhead. In addition, the execution units of a processor aren’t optimised to the specific mathematical or data-manipulation functions being undertaken, which again leads to huge overheads.
The FPGA Approach
In the world of embedded products, a common computing-power approach is to develop dedicated hardware in an FPGA. These devices are programmed using silicon design techniques to implement processing functions much like a custom-designed chip. Many papers have been written on the relative improvements between processors, FPGAs, and dedicated hardware. Typical speed/power-consumption improvements range between a factor of 100 and 5000.
Following in that vein, a recent study performed by Plextek explored how a single FPGA could accelerate a particular form of gene sequencing. Findings revealed an increase of just under a factor of 500. This can be viewed either as a significantly shorter time period or as an equipment reduction from 500 machines to a single PC. In reality, though, the savings will be a balance of the two.
Previously, these benefits were difficult to achieve for two reasons:
-
Interfacing: Dedicated engineering was required to develop FPGA systems that could easily access data sets. Once the data set changes, new interfacing requirements arise, which means a renewed engineering effort.
-
Design cycle time: The time it takes for an algorithm engineer to explain his requirements to a digital design engineer, who must then convert it all into VHDL along with the necessary testbenches to verify the design, simply becomes too long for exploratory algorithm work.
Now both of these problems have largely been solved thanks to modern FPGA devices. The first issue is resolved with embedded processors in the FPGA, which allow for more flexible interfacing. It’s even possible to directly access FPGA devices via Ethernet or even the Internet. For example, Plextek developed FPGA implementations that don’t have to go through interface modifications any time a requirement or data set changes.
To solve the second problem, companies such as Plextek have been working closely with major FPGA manufacturers to exploit new toolsets that can convert algorithmic descriptions defined in high-level mathematical languages (e.g., Matlab) into a form that easily converts into VHDL. As a result, significant time is saved from developing extensive testbenches to verify designs. Although not completely automatic, the design flow becomes much faster and much less prone to errors.
This doesn’t remove the need for a hardware designer, although it’s possible to develop methodologies to enable a hierarchical approach to algorithm exploration. The aim is to shorten the time between initial algorithm development and final solution.
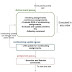
Much of the time spent during algorithm exploration involves running a wide set of parameters through essentially the same algorithm. Plextek came up with a methodology that speeds up the process by providing a parameterised FPGA platform early in the process (see the figure). The approach requires the adoption of new high-level design tools, such as Altera’s DSP Builder or Xilinx’s System Generator.

A major portion of time involved in algorithm exploration revolves around running a wide set of parameters through essentially the same algorithm. Plextek’s methodology provides a parameterized FPGA platform early in the process, which saves a significant amount of time.
A key part of the process is jointly describing the algorithm parameters that are likely to change. After they’re defined, the hardware designer can deliver a platform with super-computing power to the scientist’s local machine, one that’s tailored to the algorithm being studied. At this point, the scientist can very quickly explore parameter changes to the algorithm, often being able to explore previously time-prohibitive ideas. As the algorithm matures, some features may need updating. Though modifications to the FPGA may be required, they can be implemented much faster.
A side benefit of this approach is that the final solution, when achieved, is in a hardware form that can be easily scaled across a business. In the past, algorithm exploration may have used a farm of 100 servers, but when rolled out across a business, the server requirements could increase 10- or 100-fold, or even to thousands of machines. With FPGAs, equipment requirements will experience an orders-of-magnitude reduction.
Ultimately, companies that adopt these methodologies will achieve significant cost and power-consumption savings, as well as speed up their algorithm development flows.
 Millions of tons of food are wasted annually because 'the date'. But the date on the package is always a conservative estimate, so much food that is still good in the waste lands. Would it not be useful if the pack 'taste' of the food is still good? Researchers at the CEA-Liten, Eindhoven University of Technology, STMicroelectronics and University of Catania presented last week in the U.S. technical capstone that makes this possible - a plastic analogue to-digital converter. This gives a plastic sensor circuit of less than one euro cent feasible, which is an acceptable price increase is for example, a bag of potato chips or a piece of meat. The ultra cheap plastic electronics has many potential applications, for example in medicine.
Millions of tons of food are wasted annually because 'the date'. But the date on the package is always a conservative estimate, so much food that is still good in the waste lands. Would it not be useful if the pack 'taste' of the food is still good? Researchers at the CEA-Liten, Eindhoven University of Technology, STMicroelectronics and University of Catania presented last week in the U.S. technical capstone that makes this possible - a plastic analogue to-digital converter. This gives a plastic sensor circuit of less than one euro cent feasible, which is an acceptable price increase is for example, a bag of potato chips or a piece of meat. The ultra cheap plastic electronics has many potential applications, for example in medicine.